Overview
P-Tuning is an approach to get around the constraints / difficulty of Prompt Tuning. Discrete prompting is an NP-hard search problem over a non-differentiable landscape. We are forcing a continuous model to be steered by discrete inputs.
P-Tuning shifts the approach from Combinatorial Optimization (Discrete) to Continuous Optimization (Differentiable).
Key Mathematical Foundation
In standard interaction with an LLM, we treat the model as a function that takes a sequence of tokens from a fixed vocabulary .
Let an input sequence be and a target output be . We want to find a prompt (say a sequence of tokens ) that maximizes the likelihood of . The Objective Function:
Why this is problematic:
-
Non-Differentiable: The operation of selecting a token from vocabulary is a discrete indexing operation. You cannot compute the gradient because is not a continuous variable. The loss landscape is a series of step functions, not a smooth curve.
-
Combinatorial Explosion: If the vocabulary size is and you want a prompt of length , the search space is .
-
Local Optima: Discrete search methods (like genetic algorithms or reinforcement learning used in discrete prompt search) often get stuck in local optima because they cannot follow a gradient to the global minimum.
Note: Approaches like AutoPrompt[AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts] attempted to solve this using gradient-guided search to find discrete tokens, but they are computationally expensive and can often result in gibberish prompts (e.g., “Horse staple battery correct” might trigger a specific behavior).
The Visual Intuition:
To understand the solution, look at first layer of the Transformer: the Embedding Matrix , where is the hidden dimension. Every discrete token corresponds strictly to a single row vector in . Imagine the continuous vector space . The “valid” English words occupy only tiny, specific points in this vast space.
- Discrete Prompting: You are forced to hop only between these specific points (words).
- The Gap: The optimal vector that triggers the model to solve your task might lie in the “empty space” between the words “Translate” and “French”.
Because natural language evolved for human communication, not for steering high-dimensional neural manifolds, natural language is likely a suboptimal control language for LLMs.
Continuous Relaxation (P-Tuning Solution)
P-Tuning applies a mathematical trick common in optimization called Relaxation. We relax the constraint that our prompt tokens must be integers mapping to rows in . Instead, we define the prompt as a sequence of free vectors:
Where each .
New Objective Function:
This results in:
-
Differentiability: Because operates in continuous space, the loss function is now fully differentiable with respect to . We can use standard Backpropagation (SGD, AdamW) to optimize the prompt.
-
Expressivity: The continuous prompt space contains the discrete token space (since every word vector is a point in ), but it also contains everything in between.
- Hypothesis: Continuous prompts can encode “instructions” that are semantically impossible to express in human language but perfectly interpretable by the model’s attention mechanisms.
Initialization Setback
Let’s look at the input processing of the first Transformer block. Standard (Discrete):
The prompt vectors are frozen lookup values.
P-Tuning (Continuous):
Here, are trainable parameters.
However, P-Tuning v1 recognized a specific optimization difficulty here. If you initialize randomly (Gaussian noise), they are independent variables. But natural language is sequential; word depends on word .
If we treat as independent variables, the optimization landscape is too chaotic. The model struggles to find a “coherent” prompt because the parameters can move in opposing directions in the vector space.
Potential Fix: Very slow learning rates and extremely large models (10B+) to work. For normal scales, it is unstable.
Reparameterization
P-Tuning introduces a function to reparameterize the prompt embeddings. Instead of training the embeddings directly, we train the parameters of a small neural network (the Encoder) that generates the embeddings.
Where is typically a small LSTM or MLP, and are its parameters.
This injects an inductive bias of sequential coherence. Because processes the position index through recurrent or dense layers, the output embeddings are no longer independent. They share structure through the shared parameters .
The training now optimizes , not directly:
Where is the soft prompt generated by the encoder.
At inference time, we can discard the encoder and just use the generated embeddings directly.
Prefix-Tuning
Prefix-Tuning was developed independently around the same time as P-Tuning, with a different approach to the same problem. While P-Tuning focuses on NLU tasks and applies soft prompts only at the input layer, Prefix-Tuning targets generation tasks and applies prompts more aggressively throughout the model.
Prefix-Tuning prepends trainable “prefix” vectors to the Key and Value matrices at every Transformer layer.
For each layer , we define prefix matrices:
The attention computation becomes:
denotes concatenation along the sequence dimension.
This results in:
- Deeper Steering: P-Tuning only influences the model at the first layer. Prefix-Tuning provides “control knobs” at every layer, allowing finer-grained steering of internal representations.
- Same Reparameterization Trick: Prefix-Tuning also uses an MLP to generate the prefix vectors during training, then discards it at inference.
Comparison
| Aspect | Prompt Tuning | P-Tuning | Prefix-Tuning |
|---|---|---|---|
| Where applied | Input embeddings only | Input embeddings only | Every Transformer layer (K, V) |
| Reparameterization | No (direct optimization) | Yes (LSTM/MLP encoder) | Yes (MLP encoder) |
| Parameter count | Encoder params | ||
| Stability on small models | Poor | Better | Best |
P-Tuning v2: Fixing the Model Size Limitation
P-Tuning (v1) has a critical limitation: performance degrades significantly on smaller models (under 10B parameters).
Why Small Models Struggle
When soft prompts are applied only at the input embedding layer, their influence must propagate through all subsequent layers to affect the output. In smaller models:
- Limited Capacity: Fewer parameters means the model has less capacity to “interpret” and propagate the soft prompt signal through its layers
- Signal Dilution: The prompt’s steering effect gets diluted as it passes through each layer, and smaller models have less redundancy to preserve this signal
- Optimization Difficulty: The gradient path from loss back to the input-level soft prompts is long, making optimization harder
Empirically, P-Tuning v1 matches fine-tuning on 10B+ models but falls behind on models in the 300M-2B range.
P-Tuning v2 Solution: Deep Prompt Tuning
P-Tuning v2 applies trainable prefixes to every layer, not just the input:
This provides:
- Direct influence at each layer: No need for the prompt signal to propagate through the entire network
- Shorter gradient paths: Each layer’s prefix receives gradients directly from nearby computations
- More parameters where they matter: Instead of concentrating all trainable parameters at the input, they are distributed throughout the model
With this change, P-Tuning v2 matches fine-tuning performance even on 330M parameter models across NLU benchmarks (SuperGLUE, NER, QA).
Practical Considerations
When to Use:
- To adapt a frozen LLM to a specific task without full fine-tuning
- Compute/memory budget is limited (only soft prompt parameters are updated)
- To maintain a single base model with multiple task-specific “heads” (just swap prompts)
When NOT to Use:
- The task requires significant deviation from pre-trained knowledge
- You have sufficient resources for LoRA (Low-Rank Adaptation) or full fine-tuning (typically more performant)
Resources
-
Prefix-Tuning: Optimizing Continuous Prompts for Generation
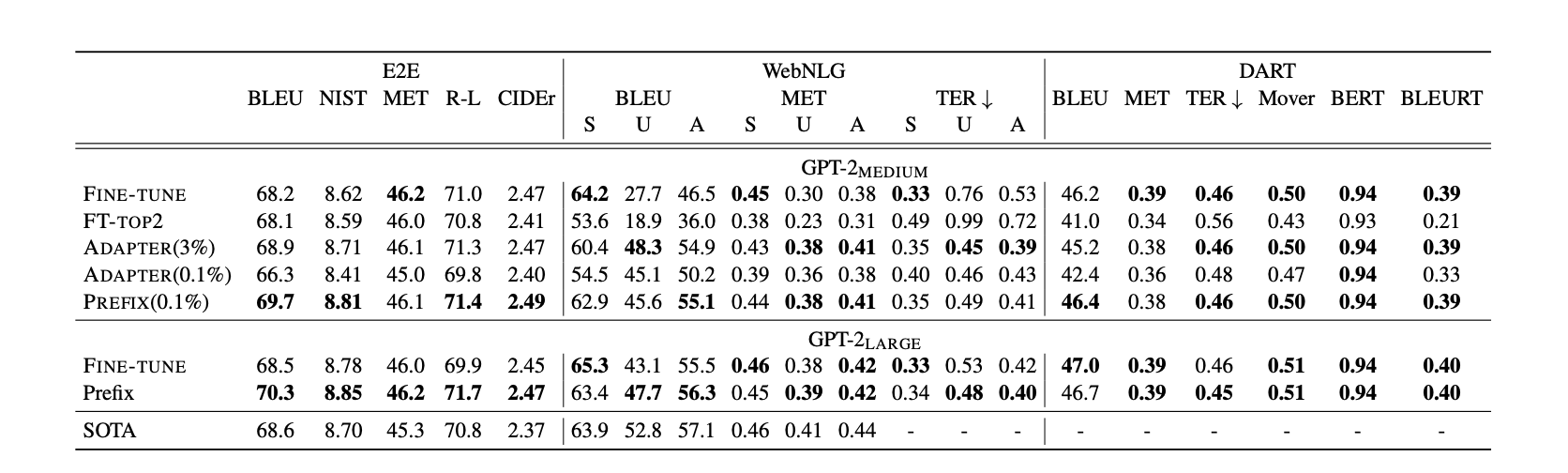 P-Tuning achieved accuracy comparable to Adapter methods.
P-Tuning achieved accuracy comparable to Adapter methods.
Back to: ML & AI Index