Overview
Agentic RAG elevates standard RAG by introducing autonomous LLM agents into the retrieval pipeline. Instead of a fixed “retrieve → augment → generate” sequence, an agentic system can reason about what to retrieve, decide when to retrieve, evaluate retrieval quality, and iteratively refine its approach until it has sufficient context to answer.
The core shift is from passive retrieval (blindly fetch top-k documents) to active retrieval (strategically gather information based on emerging needs). This transforms RAG from a static pipeline into a dynamic, goal-oriented process.
Core Concept
Why Standard RAG can fail for Complex Tasks
Naive RAG makes several assumptions that may break down in practice:
| Assumption | Reality |
|---|---|
| Top-k semantic similarity = relevance | Semantic similarity ground truth relevance |
| Single retrieval is enough | Complex questions require Multi-hop Reasoning |
| Retrieved docs are useful | Some retrievals add noise, not signal |
| Query as-is is optimal | Original query often needs transformation |
Agentic RAG addresses these failures by giving the LLM agency over the retrieval process itself.
The Agent Loop
The fundamental pattern in Agentic RAG is an iterative agent loop:
While (not confident_enough or has_info_gaps):
1. REASON: What do I know? What's missing?
2. PLAN: What tool/query should I use next?
3. ACT: Execute retrieval, web search, API call, etc.
4. OBSERVE: Evaluate the results
5. REFLECT: Is this relevant? Do I need more?
Final: SYNTHESIZE and generate response
This loop enables the system to:
- Skip retrieval when LLM parametric knowledge suffices
- Perform multiple retrievals when one is not enough
- Discard irrelevant results and try alternative queries
- Route queries to different knowledge sources based on intent
Key Agentic Capabilities
1. Adaptive Retrieval (When to Retrieve)
Unlike standard RAG which always retrieves, agentic systems decide dynamically:
- Skip retrieval: For factual questions within LLM training data
- Retrieve once: For straightforward knowledge-base queries
- Retrieve multiple times: For multi-hop questions
- Trigger web search: When internal knowledge is stale or missing
Query: "What is 2 + 2?"
Agent: [No retrieval needed - parametric knowledge sufficient]
Query: "What are our company's Q4 revenue targets?"
Agent: [Retrieve from internal docs - proprietary info]
Query: "Who founded the company that acquired Twitter?"
Agent: [Multi-hop retrieval needed]
Hop 1: Retrieve "Twitter acquisition"
Hop 2: Retrieve "[acquirer] founders"
2. Query Planning and Transformation
Agents can decompose complex queries or rewrite them for better retrieval:
- Query Decomposition: Break “Compare revenue growth of Apple and Microsoft” into parallel sub-queries
- Query Expansion: Add synonyms or related terms to improve recall
- Query Refinement: After initial retrieval, generate more specific follow-up queries
- HyDE: Generate hypothetical answer to embed as query
3. Self-Reflection and Critique
The agent evaluates its own process and outputs:
- Relevance Check: “Is this retrieved document actually relevant?”
- Sufficiency Check: “Do I have enough information to answer?”
- Consistency Check: “Do retrieved documents contradict each other?”
- Faithfulness Check: “Is my generated answer grounded in the context?“
4. Tool Use
Agents orchestrate multiple tools beyond vector retrieval:
| Tool Type | Examples |
|---|---|
| Vector Search | Query embeddings against Vector Databases |
| Keyword Search | BM25, Elasticsearch for exact matches |
| Web Search | Google for real-time information |
| SQL/API | Database queries, REST API calls |
| Code Execution | Run calculations, data transformations |
| Knowledge Graph | GraphRAG traversal for entity relationships |
5. Memory
Agents maintain state across interactions:
- Short-term: Conversation history, retrieved contexts in current session
- Long-term: Learned preferences, frequently accessed documents, user profile
Architecture Patterns
Agentic Router
A central LLM agent routes queries to appropriate tools or knowledge bases based on intent classification.

When to Use:
- Multiple knowledge sources with distinct domains
- Clear routing signals in query (e.g., “search the web for…” vs “check our docs for…“)
- Cost optimization (avoid unnecessary retrievals)
Example Routing Logic:
def route_query(query: str) -> str:
# LLM classifies intent
intent = classify_intent(query)
if intent == "factual_lookup":
return vector_rag(query)
elif intent == "real_time_info":
return web_search(query)
elif intent == "structured_data":
return sql_query(query)
elif intent == "no_retrieval_needed":
return llm_direct(query)Self-RAG (Self-Reflective RAG)
Must read: https://selfrag.github.io/
The model learns to retrieve, generate, and critique through special reflection tokens. This approach requires fine-tuning the LLM itself.
| Token | Purpose |
|---|---|
[Retrieve] / [No Retrieve] | Should I fetch external knowledge? |
[ISREL] | Is this passage relevant to the query? |
[ISSUP] | Is my generation supported by the evidence? |
[ISUSE] | Is this output useful to the user? |
Self-RAG Flow:
Query → LLM decides: [Retrieve] or [No Retrieve]?
If [Retrieve]:
→ Fetch passages
→ For each passage: LLM generates [ISREL] score
→ Filter irrelevant passages
→ Generate response with remaining context
→ LLM generates [ISSUP] score (faithfulness)
→ LLM generates [ISUSE] score (utility)
→ Select best response or iterate
Self-RAG internalizes the retrieval decision and quality evaluation into the model itself, rather than relying on external heuristics.
Trade-offs:
- Requires fine-tuning (not just prompting)
- More computationally expensive at training time
- Offers finer-grained control at inference time
- Outperforms standard RAG on factuality benchmarks
https://www.blog.langchain.com/agentic-rag-with-langgraph/ - for implementation
Corrective RAG (CRAG)
Uses a lightweight retrieval evaluator to assess document quality and trigger corrective actions.
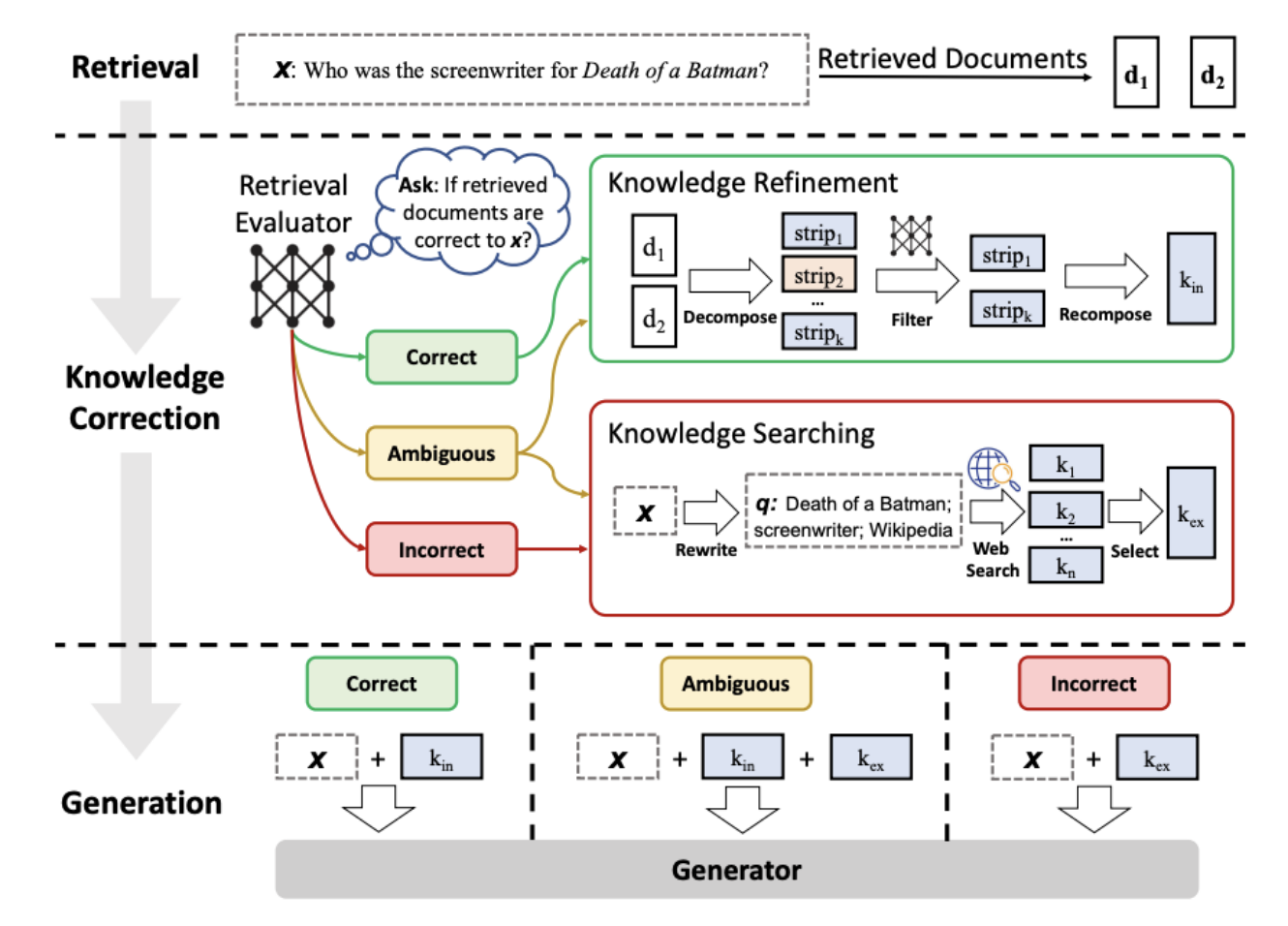
Confidence Classifications:
- Correct: High relevance → Extract and refine key knowledge strips
- Ambiguous: Uncertain → Use both retrieved docs and web search
- Incorrect: Low relevance → Discard and fall back to web search
Knowledge Refinement (for “Correct” docs):
- Decompose document into knowledge strips (sentence-level)
- Score relevance of each strip
- Filter irrelevant strips
- Recompose into focused internal knowledge
Multi-Agent RAG
Distributes the RAG workflow across specialized agents that collaborate on complex tasks.
┌─────────────────┐
│ User Query │
└────────┬────────┘
│
┌────────▼────────┐
│ Planner Agent │
│(decompose task) │
└────────┬────────┘
│
┌───────────────────┼───────────────────┐
│ │ │
▼ ▼ ▼
┌───────────┐ ┌───────────┐ ┌───────────┐
│ Retriever │ │ Retriever │ │ Retriever │
│ Agent 1 │ │ Agent 2 │ │ Agent 3 │
└─────┬─────┘ └─────┬─────┘ └─────┬─────┘
│ │ │
└───────────────────┼───────────────────┘
│
┌────────▼────────┐
│ Critic Agent │
│ (evaluate/rank) │
└────────┬────────┘
│
┌────────▼────────┐
│ Writer Agent │
│ (synthesize) │
└─────────────────┘
| Agent | Responsibility |
|---|---|
| Planner | Decompose query into sub-tasks, assign to retrievers |
| Retriever(s) | Execute searches against different sources/queries |
| Extractor | Parse and summarize retrieved documents |
| Critic | Evaluate quality, identify gaps, request re-retrieval |
| Writer | Synthesize final response from verified information |
When to Use:
- Complex research tasks requiring multiple sources
- High-stakes applications requiring quality gates
- Workflows benefiting from specialization
Comparison of Patterns
| Pattern | Complexity | Latency | Cost | Best For |
|---|---|---|---|---|
| Router | Low | Low | Low | Multi-source routing |
| Self-RAG | High (training) | Medium | Medium | Factuality-critical apps |
| CRAG | Medium | Medium | Medium | Quality-gated retrieval |
| Multi-Agent | High | High | High | Complex research tasks |
Production Considerations
Latency and Cost
Agentic RAG introduces additional latency and cost compared to Naive RAG:
| Component | Naive RAG | Agentic RAG |
|---|---|---|
| Retrieval Calls | 1 | 1-5+ (depends on complexity) |
| LLM Calls | 1 | 2-10+ (reasoning steps) |
| Typical Latency | 200-400ms | 500ms-3s+ |
| Cost per Query | Baseline | 2-10x baseline |
Mitigation Strategies:
- Set maximum iteration limits
- Use cheaper models for routing/evaluation
- Cache intermediate results
- Parallelize independent retrievals
- Implement early stopping when confidence is high
Use Agentic RAG when:
- Questions frequently require multi-step reasoning
- Users expect conversational, exploratory interactions
- Multiple heterogeneous knowledge sources exist
- Retrieval quality varies and requires evaluation
- Domain requires high factuality with citations
Don’t use Agentic RAG when:
- Queries are simple, single-hop factual lookups
- Latency SLAs are strict (<500ms)
- Cost is a primary constraint
- Your retrieval system is already high quality
- You don’t have the infrastructure for agentic orchestration
Common Pitfalls
1. Infinite Loops Agent keeps retrieving without converging on an answer.
- Fix: Set max_iterations, implement confidence thresholds
2. Over-Retrieval Agent retrieves for simple questions that don’t need it.
- Fix: Train/prompt for “no retrieval” decisions
Observability
For production agentic RAG, track:
- Iterations per query: Distribution of hop counts
- Tool usage patterns: Which tools are used most?
- Latency breakdown: Time per reasoning step, per retrieval
- Retrieval relevance per hop: Does quality degrade over iterations?
- Agent decisions: Log [Retrieve]/[No Retrieve] decisions
- Fallback rate: How often does the agent loop terminate early?
Implementation Frameworks
| Framework | Agentic RAG Support |
|---|---|
| LangChain | Agents, tools, ReAct implementation |
| LlamaIndex | QueryEngine agents, SubQuestionQueryEngine |
| CrewAI | Multi-agent orchestration |
| AutoGen | Conversational multi-agent patterns |
| Semantic Kernel | Planners and plugins for agentic flows |
Resources
Papers
- Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection (Asai et al., 2023)
- Corrective Retrieval Augmented Generation (Yan et al., 2024)
- ReAct: Synergizing Reasoning and Acting in Language Models (Yao et al., 2022)
- Toolformer: Language Models Can Teach Themselves to Use Tools (Schick et al., 2023)
Articles
Back to: 01 - RAG Index